
Timeline of Systematic Data and the Development of Computable Knowledge


 1960: Hypertext
Imagining connectivity in the world's knowledge
The concept of links between documents begin to be discussed as a paradigm for organizing textual material and knowledge.
1960: Hypertext
Imagining connectivity in the world's knowledge
The concept of links between documents begin to be discussed as a paradigm for organizing textual material and knowledge.
 1960: Full-Text Search
Finding text without an index
The first full-text searching of documents by computer is demonstrated.
1960: Full-Text Search
Finding text without an index
The first full-text searching of documents by computer is demonstrated.
 1960: Medical Subject Headings (MeSH)
Organizing the world's medical knowledge
The first version of the MeSH medical lexicon goes into use.
1960: Medical Subject Headings (MeSH)
Organizing the world's medical knowledge
The first version of the MeSH medical lexicon goes into use.
 1963: ZIP Codes
ZIP (Zoning Improvement Plan) codes are introduced by the US Post Office.
1963: ZIP Codes
ZIP (Zoning Improvement Plan) codes are introduced by the US Post Office.
 1963: ASCII Code
A standard number for every letter
ASCII Code defines a standard bit representation for every character in English.
1963: ASCII Code
A standard number for every letter
ASCII Code defines a standard bit representation for every character in English.
 1963: Science Citation Index
Mapping science by citations
Eugene Garfield publishes the first edition of the Science Citation Index, which indexes scientific literature through references in papers.
1963: Science Citation Index
Mapping science by citations
Eugene Garfield publishes the first edition of the Science Citation Index, which indexes scientific literature through references in papers.
 1963: Data Universal Numbering System (D-U-N-S)
A number for every business
Dun & Bradstreet begins to assign a unique number to every company.
1963: Data Universal Numbering System (D-U-N-S)
A number for every business
Dun & Bradstreet begins to assign a unique number to every company.




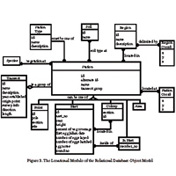 1970s: Relational Databases
Making relations between data computable
Relational databases and query languages allow huge amounts of data to be stored in a way that makes certain common kinds of queries efficient enough to be done as a routine part of business.
1970s: Relational Databases
Making relations between data computable
Relational databases and query languages allow huge amounts of data to be stored in a way that makes certain common kinds of queries efficient enough to be done as a routine part of business.
 1970—1980s: Interactive Computing
Getting immediate results from computers
With the emergence of progressively cheaper computers, it becomes possible to do computations immediately, integrating them as part of the everyday process of working with knowledge.
1970—1980s: Interactive Computing
Getting immediate results from computers
With the emergence of progressively cheaper computers, it becomes possible to do computations immediately, integrating them as part of the everyday process of working with knowledge.
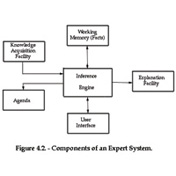 1970—1980s: Expert Systems
Capturing expert knowledge as inference rules
Largely as an offshoot of AI, expert systems are an attempt to capture the knowledge of human experts in specialized domains, using logic-based inferential systems.
1970—1980s: Expert Systems
Capturing expert knowledge as inference rules
Largely as an offshoot of AI, expert systems are an attempt to capture the knowledge of human experts in specialized domains, using logic-based inferential systems.

 1973: Lexis
Legal information goes online
Lexis provides full-text records of US court opinions in an online retrieval system.
1973: Lexis
Legal information goes online
Lexis provides full-text records of US court opinions in an online retrieval system.
 1973: Neil Sloane
Neil Sloane begins to catalog "interesting" sequences of integers.
1973: Neil Sloane
Neil Sloane begins to catalog "interesting" sequences of integers.
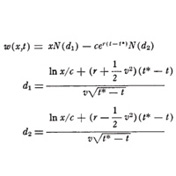 1973: Black-Scholes Formula
Bring mathematics to financial derivatives
Fischer Black and Myron Scholes give a mathematical method for valuing stock options.
1973: Black-Scholes Formula
Bring mathematics to financial derivatives
Fischer Black and Myron Scholes give a mathematical method for valuing stock options.







 2000: Sloan Digital Sky Survey
Mapping every object in the universe
The Sloan Digital Sky Survey spends nearly a decade automatically mapping every visible object in the astronomical universe.
2000: Sloan Digital Sky Survey
Mapping every object in the universe
The Sloan Digital Sky Survey spends nearly a decade automatically mapping every visible object in the astronomical universe.
 2000: Digital Object Identifier
DOI as a persistent handle is standardized
The fingerprint of any scientific document, the Digital Object Identifier has increased the visibility of and access to scientific publications while ensuring the intellectual property of each piece of work remains intact.
2000: Digital Object Identifier
DOI as a persistent handle is standardized
The fingerprint of any scientific document, the Digital Object Identifier has increased the visibility of and access to scientific publications while ensuring the intellectual property of each piece of work remains intact.
 2000: Web 2.0
Societally organized information
Social networking and other collective websites define a mechanism for collectively assembling information by and about people.
2000: Web 2.0
Societally organized information
Social networking and other collective websites define a mechanism for collectively assembling information by and about people.


 2009: Wearable Biometric Device
Consumer electronics companies like Fitbit begin releasing activity trackers that track movement, steps and heart rate through signal processing, uploading data via the internet to a cloud service to be processed and analyzed.
2009: Wearable Biometric Device
Consumer electronics companies like Fitbit begin releasing activity trackers that track movement, steps and heart rate through signal processing, uploading data via the internet to a cloud service to be processed and analyzed.
 2009: Wolfram|Alpha
An engine for computational knowledge
Wolfram|Alpha is launched as a website that computes answers to natural-language queries based on a large collection of algorithms and curated data.
2009: Wolfram|Alpha
An engine for computational knowledge
Wolfram|Alpha is launched as a website that computes answers to natural-language queries based on a large collection of algorithms and curated data.

1960
1960: Hypertext
Imagining connectivity in the world's knowledge
The concept of links between documents begin to be discussed as a paradigm for organizing textual material and knowledge.

1960: Full-Text Search
Finding text without an index
The first full-text searching of documents by computer is demonstrated.

1960: Medical Subject Headings (MeSH)
Organizing the world's medical knowledge
The first version of the MeSH medical lexicon goes into use.

1962: First GIS system
Computerizing geographic information
Roger Tomlinson initiates the Canada Geographic Information System, creating the first GIS system.
1963: ASCII Code
A standard number for every letter
ASCII Code defines a standard bit representation for every character in English.
1963: Science Citation Index
Mapping science by citations
Eugene Garfield publishes the first edition of the Science Citation Index, which indexes scientific literature through references in papers.
1963: Data Universal Numbering System (D-U-N-S)
A number for every business
Dun & Bradstreet begins to assign a unique number to every company.

1964: Abramowitz and Stegun
Collecting mathematical functions
The National Bureau of Standards (now NIST) publishes tables and properties of many higher mathematical functions
1966: Freedom of Information Act
US President Lyndon Johnson signs the act into law, mandating public access to government records.

1966: SBN Codes
A number for every book
British SBN codes are introduced, later generalized to ISBN in 1970.

1967: DIALOG
Retrieving information from anywhere
The DIALOG online information retrieval system becomes accessible from remote locations.

1968: MARC
Henriette Avram creates the MAchine-Readable Cataloging system at the Library of Congress, defining metatagging standards for books.
1970
1970s: Relational Databases
Making relations between data computable
Relational databases and query languages allow huge amounts of data to be stored in a way that makes certain common kinds of queries efficient enough to be done as a routine part of business.
1970—1980s: Interactive Computing
Getting immediate results from computers
With the emergence of progressively cheaper computers, it becomes possible to do computations immediately, integrating them as part of the everyday process of working with knowledge.
1970—1980s: Expert Systems
Capturing expert knowledge as inference rules
Largely as an offshoot of AI, expert systems are an attempt to capture the knowledge of human experts in specialized domains, using logic-based inferential systems.

1972: Karen Spärck Jones
Inverse document frequency
Karen Spärck Jones, a computer scientist known for her work on information retrieval and natural language processing, is responsible for the concept of inverse document frequency, which underlies most modern search engines.

1973: Lexis
Legal information goes online
Lexis provides full-text records of US court opinions in an online retrieval system.
1973: Black-Scholes Formula
Bring mathematics to financial derivatives
Fischer Black and Myron Scholes give a mathematical method for valuing stock options.


1976: International Standard Serial Number
Systematizing serial publications
The International Organization for Standardization (ISO) implements an eight-digit coded system to serve as a bibliographic tool for students, librarians and researchers to uniquely identify articles, specific text volumes and other serialized publications.
1980
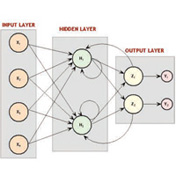
1980s: Neural Networks
Handling knowledge by emulating the brain
With precursors in the 1940s, neural networks emerge in the 1980s as a concept for storing and manipulating various types of knowledge using connections reminiscent of nerve cells.

1982: GenBank
Collecting the codes of life
Walter Goad at Los Alamos founds GenBank to collect all genome sequences being found.

1983: DNS
The Domain Name System for hierarchical Internet addresses is created; in 1984, .com and other top-level domains (TLDs) are named.

1984: Cyc
Creating a computable database of common sense
Cyc is a long-running project to encode common sense facts in a computable form.

1988: Mathematica
Language for algorithmic computation
Mathematica is created to provide a uniform system for all forms of algorithmic computation by defining a symbolic language to represent arbitrary constructs and then assembling a huge web of consistent algorithms to operate on them.

1989: The Web
Collecting the world's information
The web grows to provide billions of pages of freely available information from all corners of civilization.
1990

1991: Gopher
Burrowing around the internet
Gopher provides a menu-based system for finding material on computers connected to the internet.

1991: Unicode
Representing every language
The Unicode standard assigns a numerical code to every glyph in every human language.


1993: Tim Berners-Lee
A catalog of the web
Tim Berners-Lee creates the Virtual Library, the first systematic catalog of the web.

1994: QR Codes
Quick Response (QR) scannable barcodes are created in Japan, encoding information for computer eyes to read.


1996: The Internet Archive
Saving the history of the web
Brewster Kahle founds the Internet Archive to begin systematically capturing and storing the state of the web.

1998: Google
An engine to search the web
Google and other search engines provide highly efficient capabilities to do textual searches across the whole content of the web.

1999: Internet of Things (IoT)
The Internet of Things (IoT) is the inter-networking of physical devices embedded with connectivity and software that enable these objects to collect and exchange data.
2000
2000: Sloan Digital Sky Survey
Mapping every object in the universe
The Sloan Digital Sky Survey spends nearly a decade automatically mapping every visible object in the astronomical universe.
2000: Digital Object Identifier
DOI as a persistent handle is standardized
The fingerprint of any scientific document, the Digital Object Identifier has increased the visibility of and access to scientific publications while ensuring the intellectual property of each piece of work remains intact.

2000: Web 2.0
Societally organized information
Social networking and other collective websites define a mechanism for collectively assembling information by and about people.
2001: Wikipedia
Self-organized encyclopedia
Volunteer contributors assemble millions of pages of encyclopedia material, providing textual descriptions of practically all areas of human knowledge.

2002: A New Kind of Science
Exploring the computational universe
Stephen Wolfram explores the universe of possible simple programs and shows that knowledge about many natural and artificial processes could be represented in terms of surprisingly simple programs.

2003: Human Genome Project
The complete code of a human
The Human Genome Project is declared complete in finding a reference DNA sequence for every human.

2004: Facebook
Capturing the social network
Facebook begins to capture social relations between people on a large scale.
2004: OpenStreetMap
Steve Coast initiates a project to create a crowdsourced street-level map of the world.

2008: Blockchain
Cryptographic transactions and distributed ledgers
Satoshi Nakamoto invents blockchain as the public transaction ledger for Bitcoin.
2009: Wearable Biometric Device
Consumer electronics companies like Fitbit begin releasing activity trackers that track movement, steps and heart rate through signal processing, uploading data via the internet to a cloud service to be processed and analyzed.
2009: Wolfram|Alpha
An engine for computational knowledge
Wolfram|Alpha is launched as a website that computes answers to natural-language queries based on a large collection of algorithms and curated data.
2010

2014: Digital Assistants
Digital assistants like Siri, Cortana and Alexa that perform digital speech recognition to automate a variety of consumer or industrial applications become popular.

2017: The Wolfram Data Repository
Making public data computable
The Wolfram Data Repository makes public data computable and accessible while also keeping it securely stored.
We're continuing to update this timeline... Do you know some history we don't?
![]() We want your input »
We want your input »